

Lately we had quite a lot of of us ask about Numenta. The corporate touts itself as with the ability to effectively handle information on CPUs resulting in some eye-popping efficiency figures. What’s extra, the corporate doesn’t want giant batch sizes to generate quick AI inference figures. As a substitute, it’s utilizing options like Intel AMX and AVX-512 collectively, plus software program managing sparsity, to hurry up AI inference.
Just a few weeks in the past, Intel put collectively a short on the answer since Numenta is doing AI inference utilizing its customized directions and requested if I wished to do a chunk on it. Then I noticed the presentation at Sizzling Chip 2023, and I used to be one of many of us within the viewers who thought the presentation was cool, so I stated I’d do it. As such, we’re going to say Intel is sponsoring this piece, however many of the data is from Sizzling Chips.
Numenta Has the Secret to AI Inference on CPUs just like the Intel Xeon MAX
Numenta has been round for a very long time. It was based in 2005 by Jeff Hawkins and Donna Dubinsky. For the readers on the market, Jeff’s guide “A Thousand Brains” is at the moment Amazon’s #12 finest vendor in Pc Science (Audible Books & Originals) and #53 in Synthetic Intelligence & Semantics. (Amazon Affiliate Hyperlink.) The corporate’s aim is one we now have heard many instances earlier than, which is to use extra of the best way the mind works to AI issues.
That is most likely not the official tagline, however consider it as neuroscience-inspired AI. For the reason that human mind makes use of one thing like 20W and is ready to out-pace computer systems that use order of magnitudes extra energy than that, it’s a widespread theme within the business. In the present day’s computer systems are designed for dense compute. The human mind is designed for lots of sparse compute. In case you are not accustomed to dense versus sparse compute right here, an imperfect however fast psychological mannequin is to think about dense compute as making an attempt to compute each permutation and sparse compute as computing solely essentially the most related and impactful mixtures.
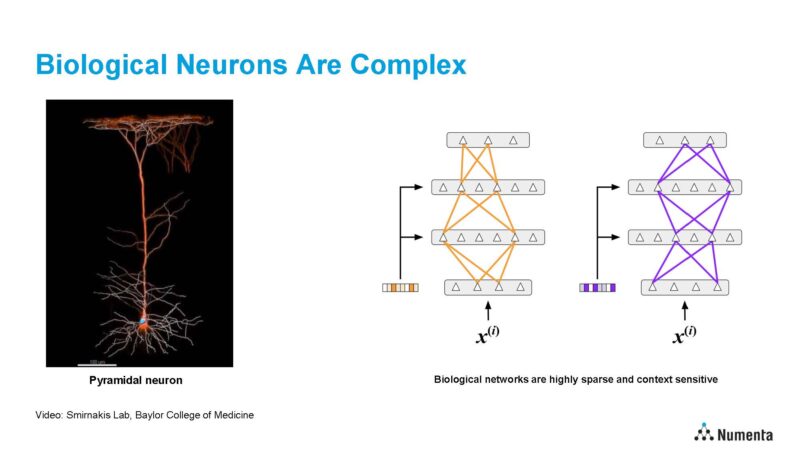
Neurons are advanced, however the mind works in a realm of ultra-sparsity. Organic mind studying is dynamic and sparse, connections are sparse, activations and routings are sparse, and so forth. Brains additionally make the most of contextual routing. When an enter is available in, the mind determines the extremely sparse a part of the community that’s going to be related, after which routes based mostly on the enter and context. In the present day, most organizations are utilizing extra of a brute pressure dense computation for AI.
Numenta’s work years in the past with Xilinx confirmed two orders of magnitude in throughput, latency, and higher energy effectivity with related accuracy. Now, the corporate is making use of its algorithms to new CPU {hardware}. Numenta discovered that it will possibly get extremely sparse, eradicating 90% of the weights whereas delivering related accuracy.
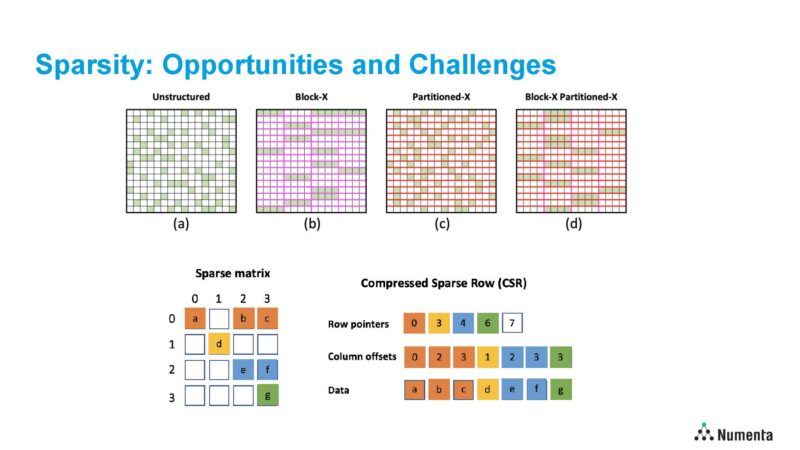
CPUs and GPUs at present are designed for dense matrix multiply compute. These extra general-purpose processors have comparatively deep pipelines, excessive clock speeds, and massive vector engines, so information must be staged to fill these compute assets. Sparsity is designed to ship the other, much less information to compute.

Sparsity is a large problem for contemporary CPUs and GPUs. Fashionable CPUs/ GPUs have deep pipelines and massive vector engines that must be persistently stuffed to run effectively. For an ideal instance of this, Numenta shared the optimized Intel Math Kernel Library (MKL) utilizing AVX-512 and 1024×1024 information matrix. Right here CSR (Compressed Sparse Row) is unstructured sparsity and BSR is block-structured sparsity. 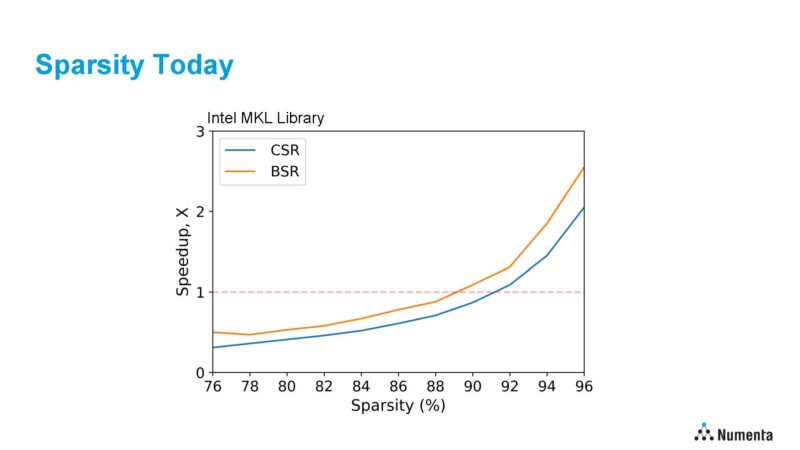
Numenta HotChips 2023 Sparsity In 2023The CPU wants ~90% sparsity utilizing AVX-512 and Intel MKL to interrupt even by simply operating a dense matrix. That is among the key challenges. Sparsity is a well known path to rising efficiency, however trendy CPUs suck at utilizing sparsity as a result of they’re designed for dense compute.

That’s Numenta’s focus level. Fixing the effectivity of sparse compute in LLMs and different giant AI fashions however with a catch. As a substitute of constructing a domain-specific AI accelerator, the corporate is targeted on bringing higher efficiency to extra general-purpose silicon.
Numenta’s method (it says) works on CPUs and GPUs, however the firm needed to prioritize, so it went after the Intel Xeon CPUs since these are nonetheless essentially the most plentiful available in the market. The earlier Numenta product model used AVX-512. The brand new product makes use of AVX-512 plus AMX. We did a chunk on AMX with pre-production silicon a couple of 12 months in the past, however we didn’t use Numenta on the time.
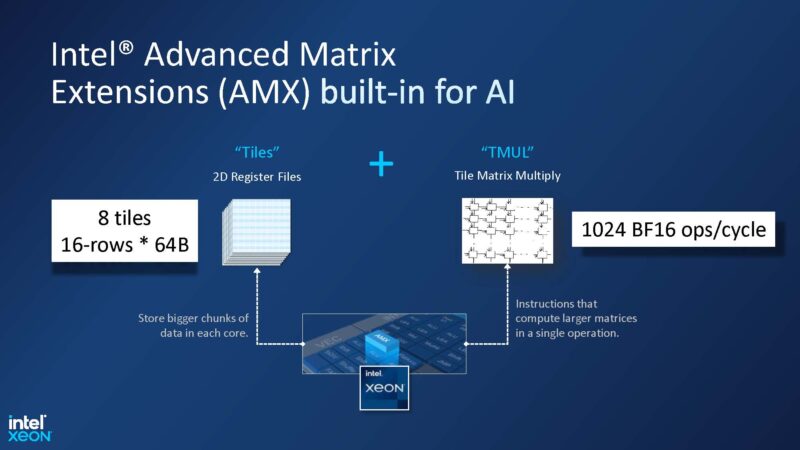
Right here is a number of the secret sauce. Numenta is utilizing AVX-512 and AMX collectively. For instance, AMX outputs into FP32 so AVX-512 can be utilized to downconvert FP32 to BF16 to feed into AMX once more. Numenta says one of many huge challenges is that in each the AVX-512 and AMX circumstances, the idea within the {hardware} is that they’re designed for dense matrix multiplication.

Numenta’s method is to deal with the complexity of sparsity in software program, then use the AVX-512 and AMX to do dense math. Or one other approach to put it, Numenta is abstracting away sparsity in order that the huge compute items can proceed to function on dense information. That retains the {hardware} operating at almost full pace avoiding the state of affairs the place we want 90% sparsity or extra to get a speedup.

In Intel’s case research on Numenta and Sapphire Rapids with AMX, had quite a lot of efficiency comparability factors that confirmed an enormous speed-up. We want that Intel-Numenta additionally did testing on Genoa, Bergamo, and Genoa-X for a extra full image. AMD’s EPYC elements should not have AMX, however it could have been a extra related comparability level to Sapphire Rapids.
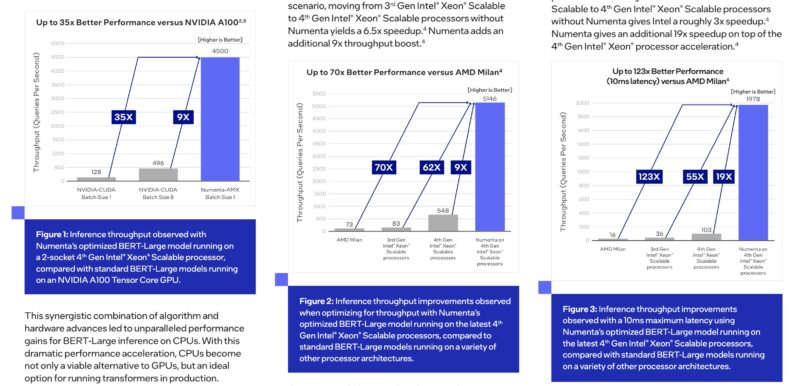
Throughout its HC2023 speak, Numenta confirmed BERT-Massive with third Technology Xeon Scalable “Ice Lake” not “Cooper Lake“, Milan, Sapphire Rapids – 19x versus Intel AMX with MKL.
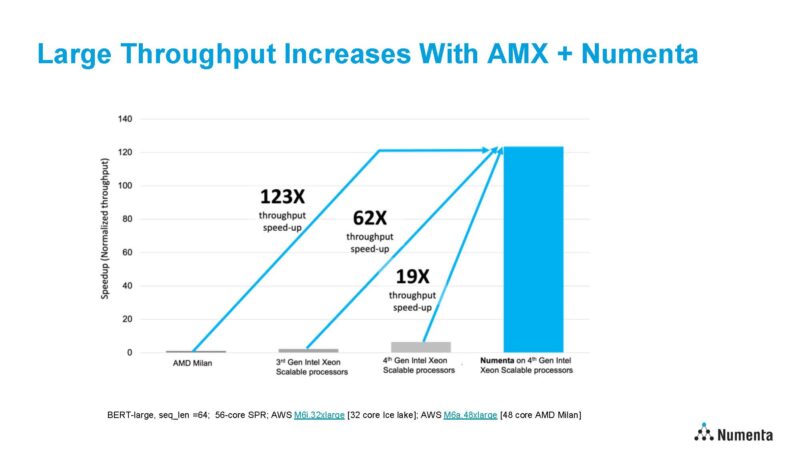
Right here is an attention-grabbing one. Numenta took a workload that NVIDIA reported A100 efficiency figures on, and ran it on a twin socket 48-core Sapphire Rapids server on AWS. It noticed linear scaling as much as 48 cores. Every shopper is operating its personal BERT-Massive occasion so it places strain on cache and reminiscence subsystems. In both case, it’s sooner than the NVIDIA A100.
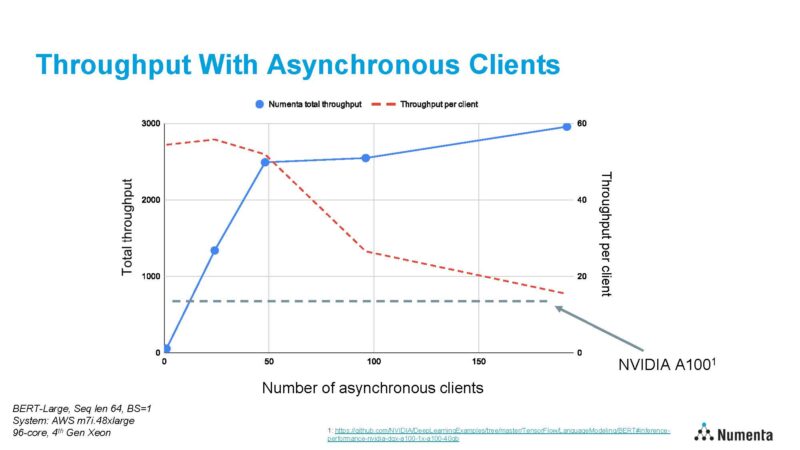
I’ve to confess, with scaling like that, I’d need to see what a Xeon MAX 9480 HBM-enabled half would do in single and twin socket mode. We returned our take a look at system and we may have a chunk on the Intel Developer Cloud subsequent month, so hopefully, new numbers can come out on these chips (Do 56 cores assist? Is a single socket higher? Does HBM have an effect?)
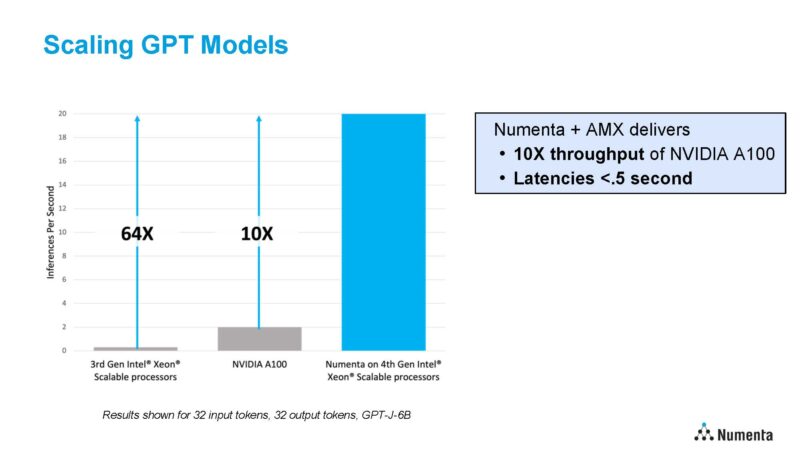
Generative AI can have its place nevertheless it has increased prices. So the aim can also be to shift the associated fee curves of attaining accuracy by altering the compute necessities for fashions.
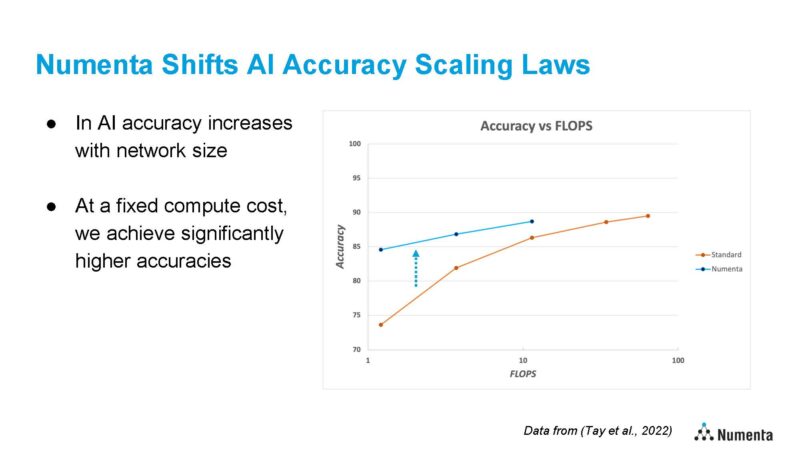
One of many cool bits right here was that Numenta has additionally run on Intel Xeon MAX CPUs, and located that on bigger fashions which might be reminiscence bandwidth constrained, they’ll stand up to 3x throughput enhancements.

As a enjoyable one, our Xeon MAX article was written and the video was virtually performed once I noticed this.
It was neat to see some real-world non-HPC use circumstances for Xeon MAX whereas doing a chunk on it.
Ultimate Phrases
Since Sizzling Chips 2023, Numenta productized this resolution with a scalable and safe LLM service for issues like sentiment evaluation, summarization, Q&A, doc classification, content material creation, and code era. They name this NuPIC or the Numenta Platform for Clever Computing.
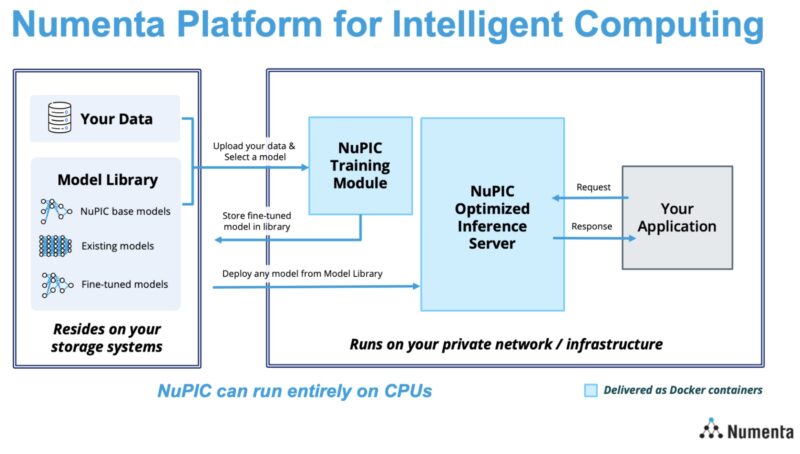
It delivers the service through docker containers and it will possibly run on an organization’s non-public infrastructure to maintain information secure.
Sizzling Chips may be very cool as a result of there are a number of very good folks in the identical room. I used to be sitting subsequent to Invoice Dally after his keynote watching these shows for example. The viewers was very enthusiastic about Numenta’s resolution as a result of it solved the issue of AI inference utilizing CPUs that had been already generally deployed, or maybe higher stated, simpler to get ahold of than supply-constrained NVIDIA GPUs, not-yet-released AMD GPUs, Intel Gaudi2 (that has develop into standard sufficient it’s beginning to see provide constraints) or different accelerators. This runs on commonplace servers.