Some particulars are rising on Europe’s first exascale system, codenamed “Jupiter” and to be put in on the Jülich Supercomputing Middle in Germany in 2024. There was a whole lot of hypothesis about what Jupiter will embody for its compute engines and networking and who will construct and keep the system. We now know a few of this and may infer some extra from the statements that have been made by the organizations taking part within the Jupiter effort.
In June 2022, the Forschungszentrum Jülich in Germany, which has performed host to many supercomputers because it was based in 1987, was chosen to host the primary of three European exascale-class supercomputers to be funded by the EuroHPC Joint Enterprise and thru the European nationwide and state governments nations who’re primarily paying to verify these HPC and AI clusters are the place they need them. With Germany having the most important economic system in Europe and being a heavy consumer of HPC because of its manufacturing focus, Jülich was the apparent place to park the primary machine in Europe to interrupt the exaflops barrier.
That barrier is as a lot an financial one as it’s a technical one. The six-year finances for Jupiter weighs in at €500 million, which is round $526.1 million at present trade charges between the US greenback and the European euro. That’s in the identical ballpark value as what the “Frontier” exascale machine at Oak Ridge Nationwide Laboratory and the “El Capitan” machine that’s being put in proper now at Lawrence Livermore Nationwide Laboratory – each of that are based mostly on a mixture of AMD CPUs and GPUs and Hewlett Packard Enterprise’s Slingshot variant of Ethernet with HPE because the prime contractor.
Everyone is aware of that Jupiter was going to make use of SiPearl’s first technology Arm processor based mostly on the Neoverse “Zeus” V1 core from Arm Ltd, which is codenamed “Rhea” by SiPearl and which is acceptable since Zeus and Jupiter are the identical god of sky, thunder, and lightning – the Greek “Zeus Pater” with a Celtic accent turns into “Jupiter”. Rhea, in fact, is the spouse of Cronos and the mom of Zeus within the Greek and subsequently Roman mythology. It’s a pity that the French semiconductor startup couldn’t do a design based mostly on the Neoverse “Demeter” V2 core – the one which Nvidia is utilizing in its “Grace” Arm server CPU. However frankly, the CPU host isn’t as vital because the GPU accelerators with regards to vector and matrix math oomph. To make sure, the vector efficiency of the CPU host is vital for all-CPU functions that haven’t been ported to accelerators or can’t simply or economically be ported to GPUs or other forms of accelerators, and there may be each indication that the Rhea1 chips will have the ability to do these jobs higher than present supercomputers at Jülich. We will see when extra feeds and speeds of the system are introduced on the upcoming SC23 supercomputing convention in Denver subsequent month.
The phrase on the road is that the 1 exaflops determine that the EuroHPC venture and that Jülich has talked about when referring to the Jupiter system is a metric gauging the Excessive Efficiency Linpack (HPL) benchmark efficiency on this method, and that permits us to do some tough math on what number of accelerators may be within the Jupiter machine and what the height theoretical efficiency of the Jupiter machine may be.
Again in June final 12 months, we didn’t assume that Jülich was going to be utilizing Intel’s “Ponte Vecchio” Max Collection GPUs in Jupiter, though there could also be a partition for just a few dozen of those units in there simply to present Intel one thing to speak about. And the reason being easy: The Intel GPUs burn much more energy than AMD and Nvidia alternate options for a given efficiency. We additionally didn’t assume Jülich would have the ability to get its palms on sufficient of AMD’s “Antares” Intuition MI300X or MI300A GPU accelerators to construct an exaflops-class system, however once more, we predict there’ll most likely be a partition inside Jupiter based mostly on AMD GPUs so researchers can do bakeoffs between architectures.
This week, EuroHPC confirmed that Nvidia was supplying the accelerators for the GPU Booster modules that may account for the majority of the computational energy within the Jupiter system.
As was the case with the LUMI pre-exascale system at CSC Finland, EuroHPC is taking a modular method to the Jupiter system, as you possibly can see under:


The Common Cluster on the coronary heart of the system is the one based mostly on the SiPearl Rhea1 CPUs, which is also referred to as the Cluster Module within the EuroHPC shows. No particulars got about what Nvidia expertise can be deployed within the Booster Module. We walked by the attainable situations to get to 1 exaflops in our June 2022 protection, and only for the heck of it we’re going to guess that EuroHPC will make the precise value/efficiency and the precise thermal alternative and make use of the PCI-Categorical variations of the “Hopper” H100 GPUs – not the SXM5 variations on the HGX motherboards which have NVSwitch interconnects to offer NUMA reminiscence sharing throughout the GPUs within a server node.
To get 1 exaflops sustained Linpack efficiency, we predict it’d take 60,000 H100 PCI-Categorical H100s, which might have a peak theoretical FP64 efficiency of round 1.56 exaflops; on FP16 processing for AI on the tensor cores, such a machine can be rated at 45.4 exaflops. All of those numbers appear impossibly giant, however that’s how the maths works out. Transferring the SXM variations of the H100 would double the watts however solely enhance the FP64 vector efficiency per GPU by 30.8 p.c, from 26 teraflops to 34 teraflops in the latest incarnations of the H100 (that are a bit sooner than they have been when introduced in the summertime of 2022). Transferring from 350 watts to 750 watts to get tighter reminiscence coupling and rather less than third extra efficiency is a nasty commerce for an energy-conscious European exascale system.
We strongly suspect that InfiniBand interconnect will probably be used within the Jupiter system, however nothing has been stated about this. Within the prior technology Juwels supercomputer, the Booster Module had a pair of AMD “Rome” Epyc 7402 processors that linked by a PCI-Categorical swap to a quad of Nvidia A100 GPUs with NVLink3 ports cross-coupled to one another with out NVSwitch interconnects, like this:
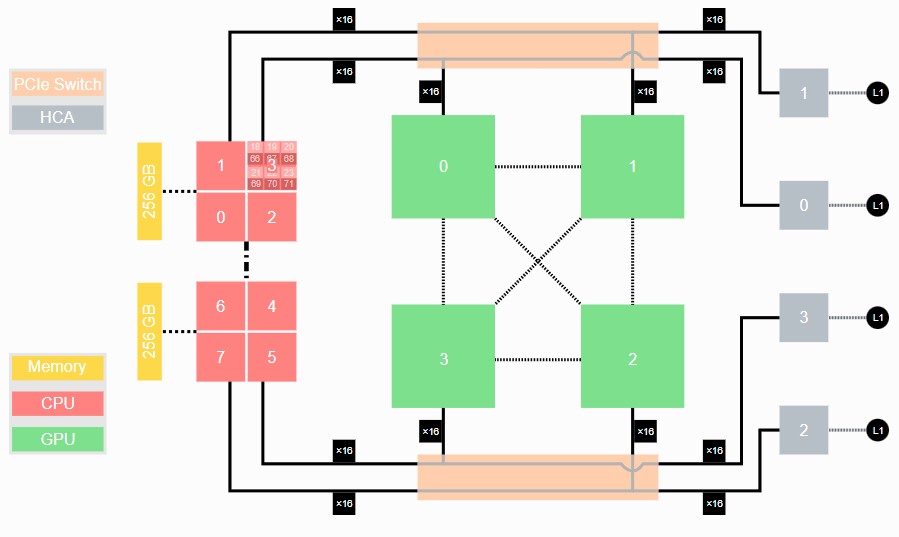

Every Rome Epyc processor had 24 cores and with SMT-2 threading turned on introduced a complete of 96 threads to the Linux working system. The Juwels node had 512 GB of reminiscence, which is fairly hefty for an HPC node however not for a GPU accelerator node. The 4 “Ampere” A100 GPUs had 40 GB of HBM2e reminiscence every, for a complete of 160 GB. On the precise facet of the block diagram, you see a quad of ConnectX-6 community interfaces from Nvidia, which supplied 4 200 Gb/sec InfiniBand ports into and out of the Booster Module. There are two PCI-Categorical 4.0 switches to hyperlink the GPUs to the InfiniBand NICs and to the CPUs.
It’s extremely doubtless that the Jupiter Booster Module will probably be an upgraded model of this setup. A Rhea1 processor might substitute the AMD processor to start out, and the Booster Modules may be outfitted with Nvidia Grace CPUs. Provided that reminiscence costs have come down, the Jupiter Booster Module will most likely have 1 TB of reminiscence, which most likely means it’s not a Grace GPU. It appears logical {that a} pair of PCI-Categorical 5.0 switches from Broadcom or Microchip will probably be used to hyperlink the CPU to the GPUs and each to the community. The PCI-Categorical model of Hopper H100 GPU has three NVLink 4 ports, to allow them to be cross coupled in a quad with out an NVSwitch within the center.
The GPU efficiency within the Jupiter Booster Module can be 3X to 6X that of the present one in Juwels (relying on sparsity and whether or not you might be doing math on the vector or tensor cores). The GPU HBM3 reminiscence can be 2X larger and the GPU reminiscence bandwidth contained in the booster, at 9.4 TB/sec, can be 1.6X that of the A100 quad. It appears apparent that Jupiter would use a hierarchy of 400 Gb/sec Quantum 2 InfiniBand switches to hyperlink this all collectively. At 60,000 GPUs, we’re speaking about 15,000 nodes only for the Booster Modules in Jupiter. There’ll most likely be a few tens of petaflops throughout the Cluster Modules within the CPU-only partitions.
There may be additionally an opportunity that Jupiter relies on the next-gen “Blackwell” GPUs, which may very well be a doubled-up GPU in comparison with the Hopper H100s with a a lot lower cost and far fewer of them. So possibly it’s extra like 8,000 nodes with a Blackwell, which works out to 32,000 GPUs. We anticipate for Blackwell to be Nvidia’s first chiplet structure, and that may assist drive the fee down in addition to the variety of models required.
These are, in fact, simply guesses.
Right here is how this conjectured Jupiter machine would possibly stack as much as different huge AI/HPC programs we’ve got seen constructed previously couple of months and its exascale friends in the US:
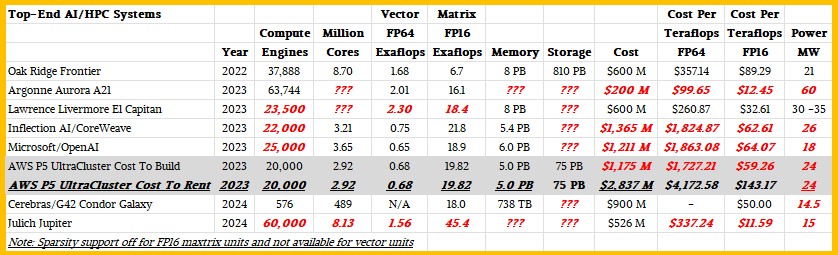

As you possibly can see, Jupiter can compete with Frontier by way of FP64 value/efficiency, however is not going to beat El Capitan and none of them come near the artificially lowered value of Aurora given the $300 million writeoff Intel took in opposition to the cope with Argonne.
Everybody suspected that the Eviden HPC division of Atos can be the prime contractor on the Jupiter deal, and certainly this has come to cross. The compute parts will probably be put in within the liquid-cooled BullSequana XH3000 system, which we detailed right here again in February 2022. German supercomputing and quantum computing vendor ParTec is supplying the ParaStation Modulo working system, which is a customized Linux platform with an MPI stack and different cluster administration and system monitoring instruments all built-in collectively.
EuroHPC says in an announcement that the price of constructing, delivering, putting in, and sustaining the Jupiter machine is €273 million ($287.3 million), and presumably the remaining a part of that €500 million is to construct or retrofit a datacenter for Jupiter and pay for energy and cooling for the machine. Electrical energy is thrice as costly in Germany as it’s in the US, and over six years, a 15 megawatt machine might simply eat the lion’s share of the remainder of that finances. Yeah, it’s loopy.
By the best way: We’re properly conscious that at a present avenue value of round $25,000 to $30,000 a pop for an H100 within the PCI-Categorical I/O variant that simply the price of 60,000 GPUs would add as much as $1.5 billion to $1.8 billion. One thing doesn’t add up. Possibly EuropeHPC was in a position to swing a killer pricing deal earlier than the pricing on H100s popped? We nonetheless assume it’s extra doubtless that Jupiter has 32,000 of the long run Blackwell B100 GPU accelerators, which we anticipate to have near twice the oomph of Hopper after a 3 nanometer course of shrink and maybe 4 GPU chiplets on a socket.
Set up of the Jupiter system will begin at Jülich to start with of 2024. It’s unclear when it is going to be completed, however it should nearly actually make the June or November Top500 supercomputing rankings subsequent 12 months. We stay up for seeing what this machine seems like, in and out. It’s doubtless that the CPU nodes will go in first, and that the GPU nodes will come later. We predict possibly the November record, relying on when Blackwell is out there in quantity.