It took the X86 structure fifteen years get an considerable share of datacenter compute, and it took the Arm structure about ten years to get a foothold you may measure. Maybe it’d solely take 5 years for the RISC-V structure to do the identical as a result of the hyperscalers and cloud builders are bored with not controlling their very own infrastructure fates greater than they already do.
That is definitely one thing that corporations like Tenstorrent, SiFive, Esperanto Applied sciences, and Ventana Micro Programs are relying on occurring. And given the power and need of the hyperscalers and cloud builders to regulate their very own {hardware} and software program stacks and their admission that they don’t have to design the whole lot all the way down to the transistor, we predict that corporations that each construct chiplets and license IP are going to get some enterprise from these datacenter titans to hurry up the design cycles for his or her servers.
It was solely again in December 2022 when Ventana, whose co-founders and engineers have deep expertise in designing X86 and Arm server chips, revealed the Veyron V1 server chip design, for which we did an in-depth drilldown on again in February of this yr. This processor was completely aggressive with X86 and Arm server chips of the time, and we confirmed that in our evaluation. With the Veyron V1 chiplets transport within the second half of this yr, and obtainable as FPGA emulators since final yr, you is likely to be questioning why Ventana has been so fast to get the kicker Veyron V2 within the discipline.
The reply is that Ventana needed to compete with a brand new spherical of X86 and Arm server chips which can be within the discipline and in addition shift chiplet interconnects for its RISC-V server designs on the request of the hyperscaler and cloud builders who’re in search of a leg up in creating RISC-V server chips.
The interconnect shift is a refined however essential one. With the unique Veyron V1 designs, which have been within the works for 2 years, Ventana picked the most suitable choice that was obtainable on the time for chiplet interconnects, which is known as Bunch of Wires, or BoW for brief, and which is managed by the Open Area Particular Structure group inside the Open Compute Challenge. That was about as open as an ordinary might get, notably when contemplating that Ampere Computing, Alibaba, AMD, ARM, Cisco Programs, Dell, Eliyan, Constancy Investments, Goldman Sachs, Google, Hewlett Packard Enterprise, IBM, Intel, Lenovo, Meta Platforms, Microsoft, Nokia, Nvidia, Rackspace, Seagate Know-how, Ventana, and Wiwynn have been all behind BoW and dealing on that customary for a quick, vast, and low-cost die-to-die interconnect to make the promise of blending chiplets throughout processes and distributors a actuality.
However then Intel got here together with the choice Common Chiplet Interconnect Categorical, or UCI-Categorical, customary again in March 2022, primarily spiking its personal Superior Interface Bus, a royalty-free PHY for connecting chiplets that was introduced in 2018 – effectively forward of the BoW effort. As a result of the IT trade likes technical differentiation and decisions, and Intel likes to exert extra management than it was getting within the BoW effort, UCI-Categorical was born, very like the Compute Categorical Hyperlink, or CXL, customary was shaped by Intel to place reminiscence semantics atop PCI-Categorical and adopted by nearly all people who had a competing strategy to coherent reminiscence throughout CPUs and accelerators. UCI-Categorical was endorsed out of the gate by Superior Semiconductor Manufacturing, AMD, Arm Holdings, Intel, Google, Meta Platforms, Microsoft, Qualcomm, Samsung, and Taiwan Semiconductor Manufacturing Co. HPE, IBM, and Nvidia have been lacking from the preliminary UCI-Categorical push, however they may finally come round.
Balaji Baktha, co-founder and chief govt officer of Ventana, says that in speaking 46 present and potential clients trying on the Veyron V1 and V2 CPU designs, it turned obvious that UCI-Categorical was the best way to go for chiplet interconnects. And therefore the corporate accelerated its Veyron V2 launch, which incorporates substantial RISC-V core enhancements, because it adopted UCI-Categorical reasonably than BoW for its chiplet interconnect.
Here’s a comparability of the feeds and speeds of the BoW, AIB 2.0, and UCI-Categorical 1.1 interconnects, enhances of a paper put collectively by Lei Shan, who used to work at IBM’s TJ Watson Analysis Middle on interconnect {hardware} and who’s now at Arm server chip upstart Ampere Computing:
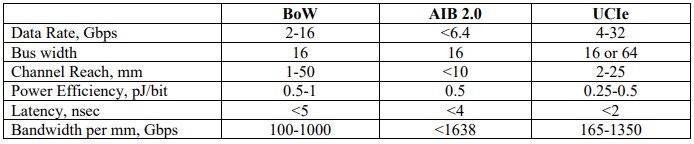

As you’ll be able to see, the information price for UCI-Categorical is 2X that of BoW and the bus bandwidth might be the identical or 4X greater. The channel attain is half the space for UCI-Categorical, however the energy effectivity is 2X higher on the hyperlinks and the latency is lower than half of that of BoW. The bandwidth per millimeter is wherever from 35 % to 65 % greater, too.
“Invariably, if chip designers need to use chiplets, they will should help to be UCI-Categorical,” Baktha tells The Subsequent Platform. “There’s a super push and quite a lot of momentum behind UCI_Express as a result of all people needs an ordinary. BoW might have been an ordinary. However we don’t need to be those who proceed to construct that going ahead as a result of the UCI customary additionally solves packaging prices successfully, and is yielding at a really optimum stage. UCI additionally solves 3D reminiscence stacking issues. So it’s simple to leverage UCI-Categorical 2.0 and bridge the hole that exists with UCI-Categorical 1.0 utilizing our personal experience – for example, UCI didn’t present hyperlinks to the AMBA CHI coherent interface bus in any respect. So we added AMBA functionality on UCI 2.0.”
The opposite large change that Ventana wished to seize shortly and put into its Veyron V2 core design was the RISC-V Vector 1.0 512-bit vector extension that’s akin to that now provided by Intel “Knights” Xeon Phi processors beginning in 2015 and in “Skylake” Xeon SP processors in 2017 and simply added to AMD “Genoa” Epyc processors a yr in the past. These 512-bit vector engines will not be actually a clone of Intel’s AVX-512 (like those within the AMD Genoa chips are on the software program stage a minimum of) however they’re shut sufficient to not create a complete software program nightmare for Linux builders who need to port their code from X86 to RISC-V. Furthermore, the 512-bit vectors will supply aggressive efficiency with X86 and Arm processors for HPC and AI workloads the place the CPU will do the mathematics reasonably than an accelerator both on the CPU bundle or exterior to the CPU like GPUs and different accelerators usually are.
Ventana has added extensions to the V2 core that enable that vector engine to help matrix operations in addition to to permit clients so as to add their very own matrix engines to the structure, both within the core or adjoining to it in a discrete chiplet utilizing UCI-Categorical hyperlinks. By the best way, the V1 core didn’t have any vector engines or matrix engine extensions, which was clearly going to be an issue since quite a lot of AI inference continues to be being performed on CPUs and in some instances AI coaching and HPC simulation and modeling can be performed on CPUs.
The opposite large change with the Veyron V2 design – we preserve saying the complete core title in order to not get confused with the “Demeter” V2 core with a pair of 256-bit vectors from Arm Ltd in its Neoverse CPU designs – is that Ventana has created a considerably improved RISC-V core.
By fusing instruction processing extra aggressively within the Veyron V2 core and making quite a lot of different tweaks, Ventana has been in a position to enhance the directions per clock (IPC) for a basket of workloads by 20 %. The highest-end clock velocity of the V2 is pushed as much as 3.6 GHz, in comparison with 3 GHz for the Veyron V1 core, too, which boosts the efficiency of the core by one other 20 %, to yield a 40 % total efficiency enhance from the V1 core to the V2 core in Ventana’s Veyron RISC-V CPU designs.
Baktha gave the keynote deal with on the RISC-V Summit 2023 convention at the moment, and revealed some extra of the speeds and feeds of the Veyron V2 chiplet advanced and potential CPU designs that Ventana clients can create utilizing its mental property and that of others.
The Veyron V2 core was designed for the 4 nanometer course of from Taiwan Semiconductor Manufacturing Co, which is a shrink from the 5 nanometer processes that have been the default design for the Veyron V1 chiplets we talked about earlier this yr. The V2 core helps the RVA23 structure profile, which has these 512-bit vector extensions as obligatory. There are additionally cryptographic features which can be run on the vector engines.
The V2 core from Ventana helps the RV64GC spec and implements a superscalar, out of order pipeline that may decode and dispatch as much as 15 directions per clock cycle. The V2 core can help Sort 1 and Sort 2 server virtualization hypervisors in addition to nested virtualization because of its IOMMU design and Superior Interrupt Structure (AIA). The core additionally has ports for debug, hint, and efficiency monitoring. All of those are desk stakes for a contemporary hyperscale datacenter server CPU. Neither the V1 nor the V2 cores have simultaneous hyperthreading, similar to the Arm cores from Amazon Net Providers and Ampere Computing don’t and the longer term ‘Sierra Glen” cores used sooner or later “Sierra Forest” Xeon SP processors is not going to.
The Veyron V2 core has 512 KB of L1 instruction cache and 128 KB of L1 information cache plus a 1 MB L2 information cache. The cores have a 4 MB slice of L3 cache related to them and throughout the 32 cores within the Veyron V2 chiplet advanced, there’s due to this fact 128 MB of cache. The cores on every chiplet are linked to one another utilizing a proprietary coherent community on chip mesh interconnect that sports activities 5 TB/sec of combination bandwidth for the cores, reminiscence, and different I/O. 4 V2 chiplets might be interlinked with UCI-Categorical to create a 128 core advanced, and when you actually need to push the boundaries, you’ll be able to hyperlink as much as six chiplets collectively to get 192 cores in a single Veyron socket.
Here’s what a V2-based CPU would possibly seem like conceptually with an I/O die and 6 32-core V2 chiplets in addition to some domain-specific accelerators linking in:
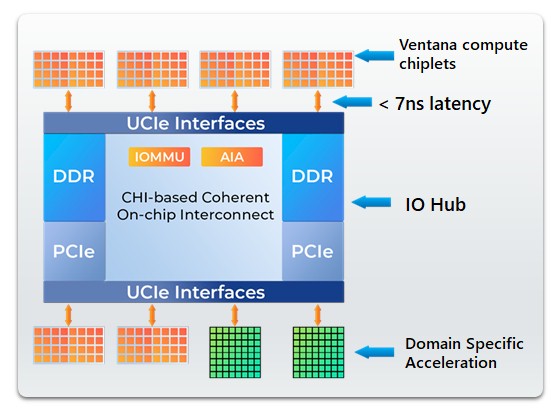

This diagram reveals hyperlinks off the I/O hub to PCI-Categorical 5.0 controllers and DDR5 reminiscence controllers, however corporations can swap in HBM3 reminiscence controllers if that’s what they need to do. The default design has twelve DDR5 reminiscence controllers throughout six V2 chiplets or eight throughout 4 V2 chiplets, which is identical sort of stability we count on to see in any server CPU as of late.
Right here is how Ventana is simulating the integer efficiency of the Veyron V2 and by way of uncooked SPECint2017rate all through per socket:
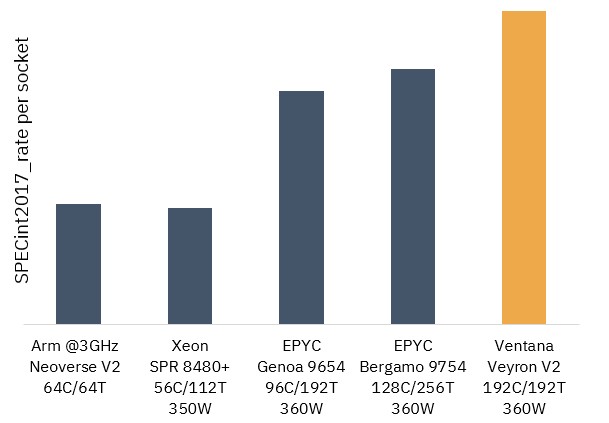

Should you do the mathematics on the chart above, a Veyron 2 RISC-V CPU with 192 cores may have about 23 % extra integer throughput than a “Bergamo” Epyc 9754 processor from AMD with 128 cores and 256 threads in the identical 360 watt energy envelope and can greatest a 96 core “Genoa” Epyc 9654 in the identical 360 watt thermal envelope by round 34 %. The efficiency hole with the 56-core “Sapphire Rapids” Xeon SP 8480+ is extra like 2.7X in favor of the Veyron V2 chip, and that’s not stunning in that it has 3.4X the cores and 1.7X the threads and even if the V2 core should be working at a decrease clock velocity. The Arm chip down appears to be a proxy for the AWS Graviton3, which with 64 cores has a tiny bit extra efficiency than the Sapphire Rapids chip proven.
Ventana is providing a baseline Veyron V2 design with 4 chiplets for 128 cores and eight DDR5 reminiscence channels with UCI-Categorical interconnects on the chiplets and an I/O bug to deliver all of them collectively within the server CPU socket. The Veyron V2 designs will probably be manufacturing prepared within the third quarter of 2024, when the UCI-Categorical 1.1 PHY that’s used to interconnect the chiplets is predicted to be obtainable.