
NVIDIA’s AI platform raised the bar for AI coaching and excessive efficiency computing within the newest MLPerf trade benchmarks.
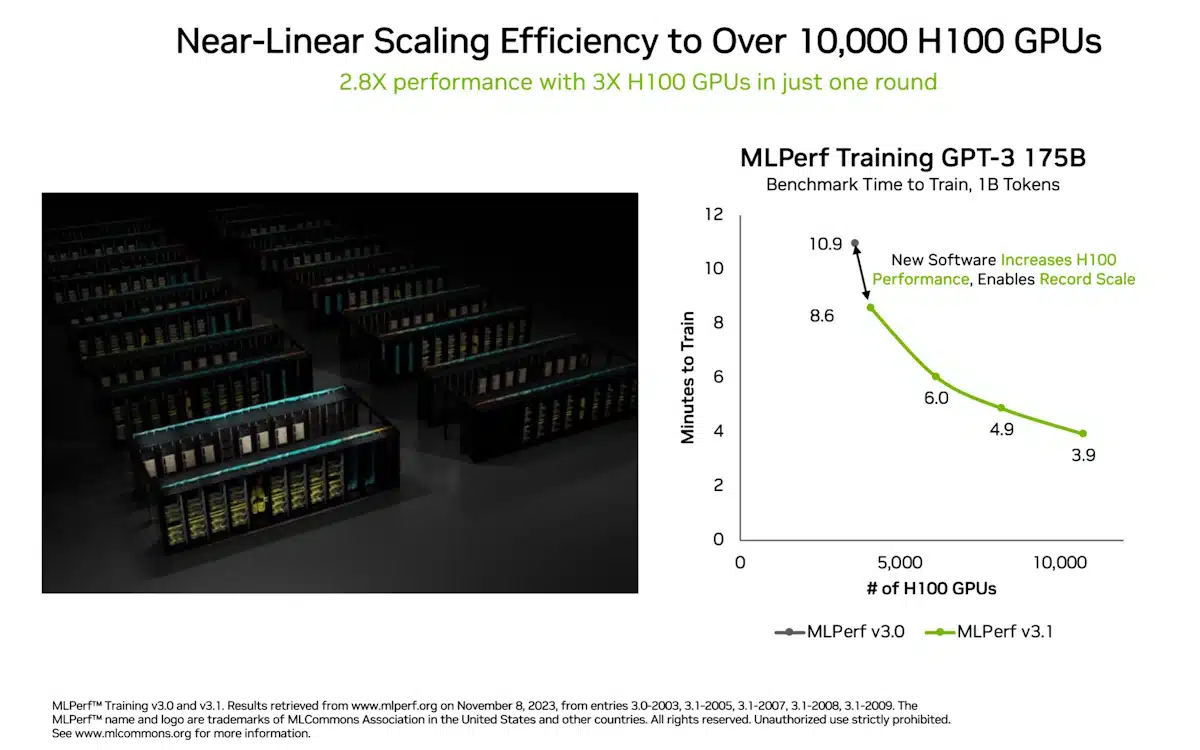
Amongst many new data and milestones, one in generative AI stands out: NVIDIA Eos — an AI supercomputer powered by a whopping 10,752 NVIDIA H100 Tensor Core GPUs and NVIDIA Quantum-2 InfiniBand networking — accomplished a coaching benchmark primarily based on a GPT-3 mannequin with 175 billion parameters skilled on one billion tokens in simply 3.9 minutes.
That’s an almost 3x achieve from 10.9 minutes, the file NVIDIA set when the check was launched lower than six months in the past.

The benchmark makes use of a portion of the complete GPT-3 knowledge set behind the favored ChatGPT service that, by extrapolation, Eos may now practice in simply eight days, 73x quicker than a previous state-of-the-art system utilizing 512 A100 GPUs.
The acceleration in coaching time reduces prices, saves vitality and speeds time-to-market. It’s heavy lifting that makes giant language fashions broadly obtainable so each enterprise can undertake them with instruments like NVIDIA NeMo, a framework for customizing LLMs.
In a brand new generative AI check this spherical, 1,024 NVIDIA Hopper structure GPUs accomplished a coaching benchmark primarily based on the Secure Diffusion text-to-image mannequin in 2.5 minutes, setting a excessive bar on this new workload.
By adopting these two assessments, MLPerf reinforces its management because the trade normal for measuring AI efficiency, since generative AI is essentially the most transformative expertise of our time.
System Scaling Soars
The most recent outcomes had been due partially to using essentially the most accelerators ever utilized to an MLPerf benchmark. The ten,752 H100 GPUs far surpassed the scaling in AI coaching in June, when NVIDIA used 3,584 Hopper GPUs.
The 3x scaling in GPU numbers delivered a 2.8x scaling in efficiency, a 93% effectivity charge thanks partially to software program optimizations.
Environment friendly scaling is a key requirement in generative AI as a result of LLMs are rising by an order of magnitude yearly. The most recent outcomes present NVIDIA’s capability to fulfill this unprecedented problem for even the world’s largest knowledge facilities.
The achievement is because of a full-stack platform of improvements in accelerators, methods and software program that each Eos and Microsoft Azure used within the newest spherical.
Eos and Azure each employed 10,752 H100 GPUs in separate submissions. They achieved inside 2% of the identical efficiency, demonstrating the effectivity of NVIDIA AI in knowledge heart and public-cloud deployments.

NVIDIA depends on Eos for a wide selection of essential jobs. It helps advance initiatives like NVIDIA DLSS, AI-powered software program for state-of-the-art pc graphics and NVIDIA Analysis tasks like ChipNeMo, generative AI instruments that assist design next-generation GPUs.
Advances Throughout Workloads
NVIDIA set a number of new data on this spherical along with making advances in generative AI.
For instance, H100 GPUs had been 1.6x quicker than the prior-round coaching recommender fashions broadly employed to assist customers discover what they’re on the lookout for on-line. Efficiency was up 1.8x on RetinaNet, a pc imaginative and prescient mannequin.
These will increase got here from a mix of advances in software program and scaled-up {hardware}.
NVIDIA was as soon as once more the one firm to run all MLPerf assessments. H100 GPUs demonstrated the quickest efficiency and the best scaling in every of the 9 benchmarks.

Speedups translate to quicker time to market, decrease prices and vitality financial savings for customers coaching huge LLMs or customizing them with frameworks like NeMo for the particular wants of their enterprise.
Eleven methods makers used the NVIDIA AI platform of their submissions this spherical, together with ASUS, Dell Applied sciences, Fujitsu, GIGABYTE, Lenovo, QCT and Supermicro.
NVIDIA companions take part in MLPerf as a result of they comprehend it’s a helpful instrument for patrons evaluating AI platforms and distributors.
HPC Benchmarks Broaden
In MLPerf HPC, a separate benchmark for AI-assisted simulations on supercomputers, H100 GPUs delivered as much as twice the efficiency of NVIDIA A100 Tensor Core GPUs within the final HPC spherical. The outcomes confirmed as much as 16x features for the reason that first MLPerf HPC spherical in 2019.
The benchmark included a brand new check that trains OpenFold, a mannequin that predicts the 3D construction of a protein from its sequence of amino acids. OpenFold can do in minutes important work for healthcare that used to take researchers weeks or months.
Understanding a protein’s construction is essential to discovering efficient medicine quick as a result of most medicine act on proteins, the mobile equipment that helps management many organic processes.
Within the MLPerf HPC check, H100 GPUs skilled OpenFold in 7.5 minutes. The OpenFold check is a consultant a part of your complete AlphaFold coaching course of that two years in the past took 11 days utilizing 128 accelerators.
A model of the OpenFold mannequin and the software program NVIDIA used to coach it will likely be obtainable quickly in NVIDIA BioNeMo, a generative AI platform for drug discovery.
A number of companions made submissions on the NVIDIA AI platform on this spherical. They included Dell Applied sciences and supercomputing facilities at Clemson College, the Texas Superior Computing Heart and — with help from Hewlett Packard Enterprise (HPE) — Lawrence Berkeley Nationwide Laboratory.
Benchmarks With Broad Backing
Since its inception in Could 2018, the MLPerf benchmarks have loved broad backing from each trade and academia. Organizations that help them embody Amazon, Arm, Baidu, Google, Harvard, HPE, Intel, Lenovo, Meta, Microsoft, NVIDIA, Stanford College and the College of Toronto.
MLPerf assessments are clear and goal, so customers can depend on the outcomes to make knowledgeable shopping for selections.
All of the software program NVIDIA used is out there from the MLPerf repository, so all builders can get the identical world-class outcomes. These software program optimizations get constantly folded into containers obtainable on NGC, NVIDIA’s software program hub for GPU purposes.
Be taught extra about MLPerf and the main points of this spherical.