
This week Nvidia shared particulars about upcoming updates to its platform for constructing, tuning, and deploying generative AI fashions.
The framework, referred to as NeMo (to not be confused with Nvidia’s conversational AI toolkit or BioNeMo for drug improvement), is designed to let customers practice large-scale fashions and is identical platform used for a latest MLPerf run on GPT-3 175B that achieved 797 teraflops per system throughout 10,752 H100 GPUs.
Dave Salvator, Director of Accelerated Computing Merchandise at Nvidia tells The Subsequent Platform that NeMo is being utilized by firms like AWS as a part of their Bedrock and Titan fashions with a number of AWS prospects leveraging that to develop their very own. He provides that different prospects, together with SAP and Dropbox are utilizing the framework and contributing insights about new options.
“The LLM house remains to be comparatively nascent and there’s nonetheless loads of discovery happening across the methods we will make the fashions smarter and extra succesful however strive to do this in a approach that doesn’t utterly crush your infrastructure, that allows you to get coaching accomplished in a sensible quantity of tie measured in days and weeks versus years and even many years,” Salvator tells us.
As famous above, the efficiency is value a glance:
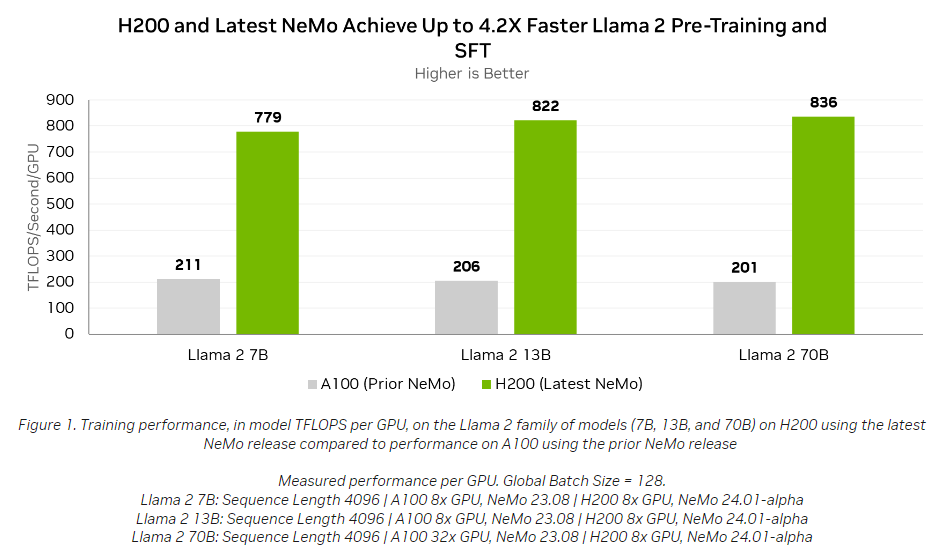

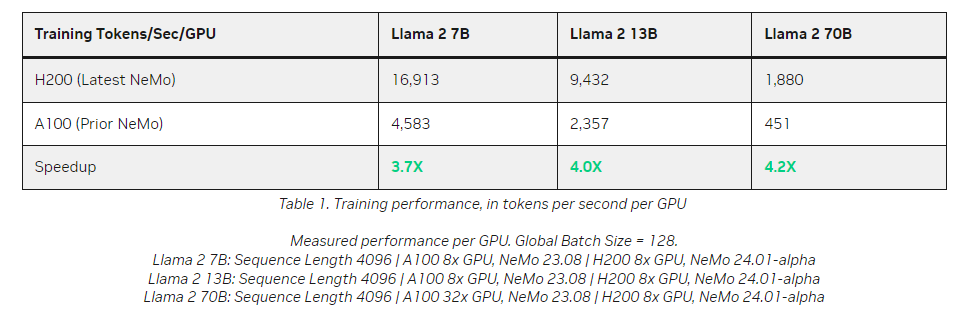

The 4.2X is achieved utilizing supervised tuning, which is a more durable option to do issues however will get a extra correct mannequin. The factor to notice is how even on the Llama fashions of various sizes (the identical structure is run with completely different hyperparameter counts between 7-70B) Nvidia is ready to preserve throughput per GPU for probably the most half.
There’s a truthful quantity of inference constructed into the LLM coaching course of (bringing knowledge in from the dataset, seeing outcomes, and updating the mannequin). When you’re doing this sort of fine-tuning, it’s not a one-shot deal: it’s iterative and prolonged. By bringing the brand new function contained in the coaching course of to do reinforcement studying with human suggestions, Salvator says customers can see a 5X efficiency bounce. In a small config of 16 GPUs on a 2m parameter mannequin the 5X is well doable and even when bumping to 129 GPUs and a commensurate mannequin dimension improve, it doesn’t fall far, if in any respect, from the 5X mark.
In line with Nvidia, following the introduction of TensorRT-LLM in October, they have been in a position to exhibit the power to run the newest Falcon-180B mannequin on a single H200 GPU, leveraging TensorRT-LLM’s superior 4-bit quantization function, whereas sustaining 99% accuracy, as detailed on this technical piece from the crew from at the moment.
Amongst different new options that helped Nvidia attain the above outcomes is the addition of absolutely sharded knowledge parallelism, one thing that’s already baked into different platforms (PyTorch, for example). To be truthful, this didn’t add any of the cited speedup (in truth, there might need been a slight hit) however it does deliver ease of use.
In essence, it’s a friendlier option to get completely different components of a mannequin to put throughout completely different GPU assets. This may imply sooner time to marketplace for fashions, Salvator says, which could cancel out among the efficiency hit however he’s assured they’ll be capable of trim down the tradeoff in successive updates.
Nvidia has additionally added mixed-precision implementations of the mannequin optimizer, which they are saying “improves the efficient reminiscence bandwidth for operations that work together with the mannequin state by 1.8X”. When you’re not knee-deep in tuning fashions, it might sound odd that mixed-precision help is simply being added however it’s not so simple as having FP8 and simply utilizing it.
As Salvator explains, “simply because FP8 is applied in {hardware}, doesn’t imply you should use it throughout the board on a mannequin and count on that it’s going to converge… We’ve got our transformer engine tech and may go layer by layer, look at the mannequin and see if a selected layer can use FP8. If we come again and see it can trigger unacceptable accuracy losses that can decelerate coaching or hold the mannequin from converging we run in FP16.”
He provides, “It’s not nearly having FP8 as a checkbox, it’s about having the ability to intelligently use it.”
One other function, referred to as Combination of Specialists (MoE) has been added, which “permits mannequin capability to be elevated with no proportional improve in each the coaching and inference compute necessities.” Nvidia says MoE architectures obtain this by way of a conditional computation strategy the place every enter token is routed to just one or a couple of knowledgeable neural community layers as a substitute of being routed by way of all of them. This decouples mannequin capability from required compute. The most recent launch of NeMo introduces official help for MoE-based LLM architectures with knowledgeable parallelism.
The MoE fashions based mostly on NeMo help knowledgeable parallelism, which can be utilized together with knowledge parallelism to distribute MoE consultants throughout knowledge parallel ranks. Nvidia says NeMo additionally supplies the power to configure knowledgeable parallelism arbitrarily. “Customers can map consultants to completely different GPUs in numerous methods with out proscribing the variety of consultants on a single system (all units, nonetheless, should comprise the identical variety of consultants). NeMo additionally helps instances the place the knowledgeable parallel dimension is lower than the info parallel dimension.:
“LLMs signify among the most fun work in AI at the moment, probably the most attention-grabbing advances are based mostly on LLMs as a consequence of their skill to textual content, laptop code, and even proteins within the case of BioNeMo. Nonetheless, all that functionality comes at a big requirement of each compute, reminiscence, and reminiscence bandwidth and full system design,” Salvator says.
“What we’re doing with NeMo framework is continuous to search out new strategies and strategies and listening to the group about what to implement first to deliver extra efficiency and ease of use to make it potential to get these fashions skilled and deployed.”