
MLCommons, the open engineering consortium for benchmarking the efficiency of chipsets for synthetic intelligence, right this moment unveiled the outcomes of a brand new check that’s geared to find out how shortly {hardware} can run essentially the most superior AI fashions.
Nvidia Corp.’s most superior chips had been the highest performers in checks on a big language mannequin, although Intel Corp.’s {hardware} got here a surprisingly shut second.
MLCommons is a vendor-neutral, multi-stakeholder group that gives a degree taking part in discipline for chipmakers to report on numerous facets of their AI efficiency utilizing the MLPerf benchmark checks. Right this moment, it introduced the outcomes of its new MLPerf Inference 3.1 benchmarks, which come within the wake of its 3.0 leads to April.
Notably, that is the primary time that MLCommons has supplied benchmarks for testing AI inference, although it’s not the primary time it has tried to validate efficiency on the massive language fashions that energy generative AI algorithms corresponding to ChatGPT.
In June, MLCommons revealed the MLPerf 3.0 Coaching benchmarks that lined LLMs for the primary time. Nonetheless, coaching LLMs is sort of a distinct factor from working inference, which refers to powering these fashions in manufacturing. With inference, LLMs are basically performing a generative process, corresponding to writing sentences or creating photographs. In coaching, these fashions are merely buying info.
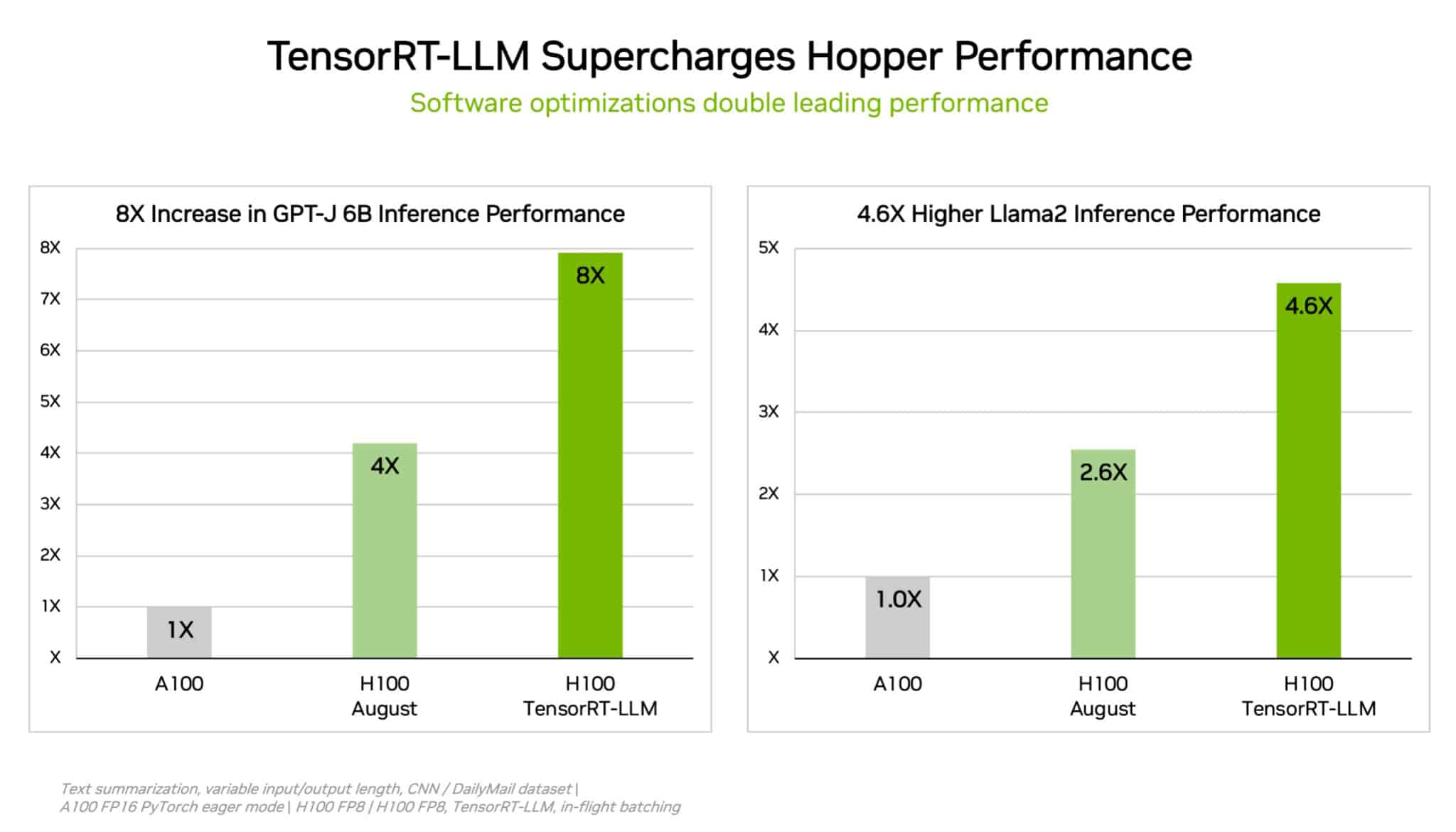
MLCommons mentioned its newest benchmark relies on an LLM with 6 billion parameters, generally known as GPT-J 6B. It’s designed to summarize texts from information articles printed by Cable Information Community and the Each day Mail. It simulates the inference a part of AI knowledge crunching, which powers generative AI instruments.
Nvidia submitted the outcomes of two of its most superior chips, together with the GH200 Grace Hopper Superchip, which hyperlinks a Hopper graphic processing unit with a Grace central processing unit in a single chip. The mixture is alleged to offer extra reminiscence, bandwidth and the power to shift duties between the GPU and an Arm-based CPU to optimize efficiency.
As well as, Nvidia submitted its HGX 100 system, which packs eight of its most superior H100 GPUs and delivers exceptionally excessive throughput.
Nvidia’s {hardware} displayed essentially the most spectacular outcomes throughout all of MLPerf’s knowledge heart checks, exhibiting the very best efficiency for duties together with pc imaginative and prescient, speech recognition and medical imaging. In addition they got here out tops by way of extra demanding workloads corresponding to LLM inference and advice methods.
The GH200 Grace Hopper Superchip proved superior to the HGX 100, with efficiency averaging round 17% higher. That’s not stunning, because the Grace Hopper chipset has extra processing energy and helps sooner networking speeds between Arm-based CPUs and the GPU.
“What you see is that we’re delivering management efficiency throughout the board, and once more, delivering that management efficiency on all workloads,” Dave Salvator, Nvidia’s accelerated computing advertising director, mentioned in a press release.
Karl Freund, founder and principal analyst of Cambrian-AI Analysis LLC, wrote in Forbes that Nvidia’s outcomes present why it stays the one to beat and why it dominates the AI trade. “As at all times, the corporate ran and received each benchmark,” Freund mentioned. “Essentially the most fascinating factor was the primary submission for Grace Hopper, the Arm CPU and the Hopper GPU Superchip, which has turn out to be the Nvidia fleet’s flagship for AI inferencing.”
Though Nvidia got here out tops, Intel Corp.’s Habana Gaudi2 accelerators, that are produced by its subsidiary Habana Labs, got here a surprisingly shut second to Nvidia’s chips. The outcomes confirmed that the Gaudi2 system was simply 10% slower than Nvidia’s system.
“We’re very pleased with the outcomes of inferencing, (as) we present the worth efficiency benefit of Gaudi2,” mentioned Eitan Medina, Habana’s chief working officer.
It’s additionally price noting that Intel’s Habana Gaudi2 relies on a seven-nanometer manufacturing node, in distinction to the five-nanometer Hopper GPU. What’s extra, Intel guarantees its system will turn out to be even sooner for AI inference duties when it’s up to date with one thing known as FP8 precision quantization later this month.
Intel guarantees that the replace will ship a two-times efficiency enhance. As well as, Intel can also be mentioned to have a 5nm Gaudi3 chipset within the works that’s more likely to be introduced later this yr.
Intel added that its Habana Gaudi2 chip will probably be cheaper than Nvidia’s system, although the corporate has not but revealed the precise value of that chip.
Nvidia isn’t standing nonetheless, although, saying it would quickly roll out a software program replace that may double the efficiency of its GH200 Grace Hopper Superchip by way of its AI inference capacity.
Different opponents who submitted outcomes embrace Google LLC, which previewed the efficiency of its newest Tensor Processing Items, however fell in need of Nvidia’s numbers. Qualcomm Inc. additionally did nicely, with its Qualcomm Cloud AI100 chipset exhibiting robust efficiency ensuing from latest software program updates. Qualcomm’s outcomes had been all of the extra spectacular as its silicon consumes far much less energy than that of its rivals.
Photographs: MLCommons
Your vote of assist is essential to us and it helps us hold the content material FREE.
One-click under helps our mission to offer free, deep and related content material.
Be a part of our neighborhood on YouTube
Be a part of the neighborhood that features greater than 15,000 #CubeAlumni specialists, together with Amazon.com CEO Andy Jassy, Dell Applied sciences founder and CEO Michael Dell, Intel CEO Pat Gelsinger and lots of extra luminaries and specialists.
THANK YOU