

As we pen this text, the NVIDIA H100 80GB PCIe is $32K at on-line retailers like CDW and is back-ordered for roughly six months. Understandably, the worth of NVIDIA’s top-end do (virtually) all the pieces GPU is extraordinarily excessive, as is the demand. NVIDIA got here out with another for a lot of AI customers and people working combined workloads within the enterprise that’s flying below the radar, however that is excellent. The NVIDIA L40S is a variant of the graphics-oriented L40 that’s rapidly changing into the best-kept secret in AI. Allow us to dive in and perceive why.
We simply wished to thank Supermicro for supporting this piece by getting us {hardware}. Since they managed to get us entry to so many hard-to-get NVIDIA components, we are going to say they’re sponsoring this piece.
NVIDIA A100, NVIDIA L40S, and NVIDIA H100
First, allow us to begin by saying that if you wish to prepare foundational fashions immediately, one thing like a ChatGPT, then the NVIDIA H100 80GB SXM5 continues to be the GPU of alternative. As soon as the foundational mannequin has been skilled, customizing a mannequin primarily based on domain-specific information or inferencing can typically be executed on considerably lower-cost and lower-power components.

Nowadays, there are three essential GPUs used for high-end inference: the NVIDIA A100, NVIDIA H100, and the brand new NVIDIA L40S. We’ll skip the NVIDIA L4 24GB as that’s extra of a lower-end inference card.

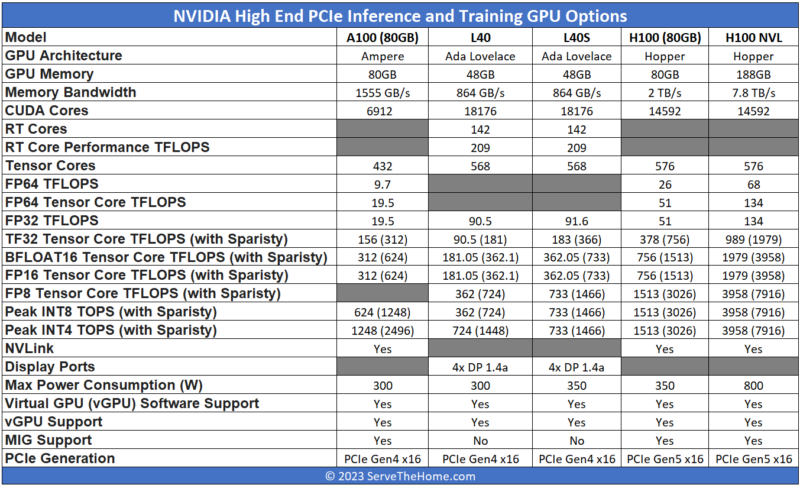
The NVIDIA A100 and H100 fashions are primarily based on the corporate’s flagship GPUs of their respective generations. Since we’re discussing PCIe as an alternative of SXM modules, the 2 most vital variations between the shape elements are NVLink and energy consumption. The SXM modules are designed for greater energy consumption (roughly twice the PCIe variations) and to be interconnected through NVLink and infrequently NVSwitch topologies in multi-GPU assemblies. You’ll be able to see an instance of one of many highest-end methods out there in our latest Supermicro SYS-821GE-TNHR 8x NVIDIA H100 AI server piece.
The NVIDIA A100 PCIe was launched in 2020 because the 40GB mannequin, after which in mid-2021, the corporate up to date the providing to the A100 80GB PCIe add-in card. Years later, these playing cards are nonetheless widespread.

We first obtained hands-on with the NVIDIA H100 SXM5 module in early 2022, however methods began exhibiting up in late 2022 and early 2023 as PCIe Gen5 CPUs grew to become out there.

The NVIDIA H100 PCIe is the lower-power H100 designed for mainstream servers. A method to think about the PCIe card is the same quantity of silicon working at a distinct a part of the voltage/ frequency curve designed for decrease efficiency but in addition a lot decrease energy consumption.

There are some variations even inside the H100 line. The NVIDIA H100 PCIe continues to be a H100, however within the PCIe type issue, it has lowered efficiency, energy consumption, and a few interconnect (e.g., NVLink speeds.)
The L40S is one thing fairly totally different. NVIDIA took the bottom L40, an information heart visualization GPU utilizing NVIDIA’s latest Ada Lovelace structure, and altered the tunings in order that it was tuned extra for AI relatively than visualization.

The NVIDIA L40S is a captivating GPU because it retains options just like the Ray Tracing cores and DisplayPort outputs and NVENC / NVDEC with AV1 assist from the L40. On the similar time, NVIDIA transitions extra energy to drive clocks on the AI parts of the GPU.

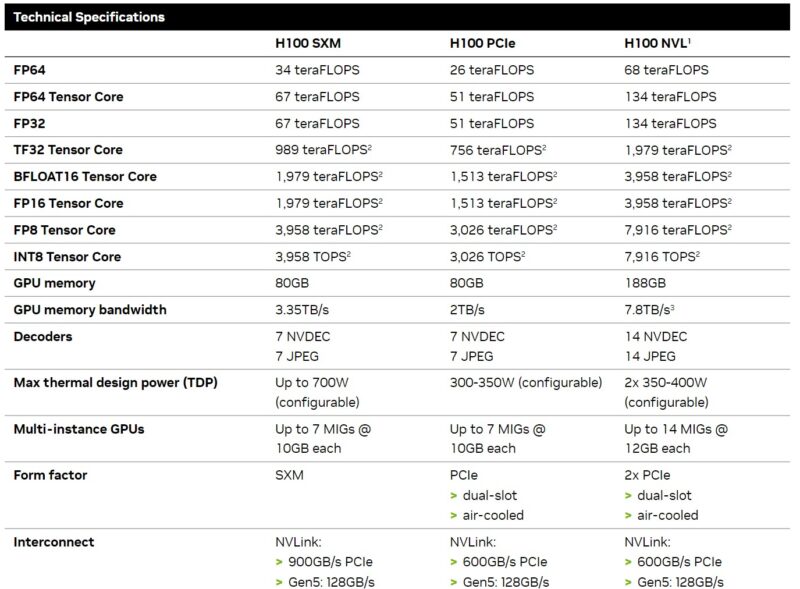
We put this on a chart to make it simpler to visualise. NVIDIA’s specs generally range even primarily based on the NVIDIA supply one views, so that is one of the best we may discover and we are going to replace it if we get an replace to the specs. We additionally included the dual-card H100 NVL that has two enhanced H100s with a NVLink bridge between them, so deal with that as a dual-card answer whereas the remaining are single playing cards.
There are just a few factors price right here:
- The L40S is a massively improved card for AI coaching and inferencing versus the L40, however one can simply see the widespread heritage.
- The L40 and L40S usually are not the playing cards if you happen to want absolute reminiscence capability, bandwidth, or FP64 efficiency. Given the relative share that AI workloads are taking on conventional FP64 compute nowadays, most folk will probably be greater than OK with this trade-off.
- The L40S might seem like it has considerably much less reminiscence than the NVIDIA A100, and bodily, it does, however that’s not the entire story. The NVIDIA L40S helps the NVIDIA Transformer Engine and FP8. Utilizing FP8 drastically reduces the dimensions of information and due to this fact, a FP8 worth can use much less reminiscence and requires much less reminiscence bandwidth to maneuver than a FP16 worth. NVIDIA is pushing the Transformer Engine as a result of the H100 additionally helps it and helps decrease the fee or enhance the efficiency of its AI components.
- The L40S has a extra visualization-heavy set of video encoding/ decoding, whereas the H100 focuses on the decoding aspect.
- The NVIDIA H100 is quicker. It additionally prices much more. For some sense, on CDW, which lists public costs, the H100 is round 2.6x the worth of the L40S on the time we’re scripting this.
- One other huge one is availability. The NVIDIA L40S is way quicker to get nowadays than ready in line for a NVIDIA H100.
The key is {that a} new widespread strategy to get forward on the AI {hardware} aspect is to not use the H100 for mannequin customization and inference. As an alternative, there’s a shift again to a well-known structure we coated a few years in the past, the dense PCIe server. In 2017, once we did DeepLearning11 a 10x NVIDIA GTX 1080 Ti Single Root Deep Studying Server cramming NVIDIA GeForce GTX 1080 Ti’s right into a server was the go-to structure for even giant corporations like search/ net hyperscalers in sure components of the world and autonomous driving corporations.

NVIDIA modified its EULA to outlaw this type of configuration, and it’s making its software program focus extra on the info heart components for AI inference and coaching, so issues are totally different now.
In 2023, take into consideration the identical idea however with a NVIDIA L40S twist (and with out server “humping.”)

One can get comparable efficiency, presumably at a cheaper price, by shopping for L40S servers and simply getting extra lower-cost GPUs than utilizing the H100.
Subsequent, allow us to dive into {that a} bit extra.